Creating Fully Reproducible, PDF/A Compliant Documents in LaTeX
A guide to creating fully reproducible, PDF/A Compliant documents in LaTeX.


{kind=link}
Hello there. I am Shen, and I study Philosophy and Computer Science. This is a guide on creating fully reproducible, PDF/A-compliant documents in LaTeX. LaTeX documents are the gold-standard in academic publishing and typesetting, and this guide will help you make your documents more accessible, better structured, and suitable for long-term preservation for the future.
This guide is suitable for the intermediate LaTeX user. You do not need to know any TeX programming at all. The method described here is compatible with existing documents and templates.
Introduction to PDF/A-Compliance, and Fully Reproducible PDFs.
We will begin with an introduction on PDF/A compliance, reproducible builds, and why they are beneficial for LaTeX documents. If you are familiar with these topics already, feel free to visit the next section instead.
What is the PDF/A standard, and why should my document be PDF/A-compliant?
The PDF/A standard is an ISO standard that aims to make PDF-documents better suited for long-term preservation and archiving. A PDF is supposed to be a paper-replacement, after all. And documents (whether digital, or paper) must be readable, even decades after they are created. LaTeX is used for many documents those long-term preservation is important, such as theses, dissertations, and documentation. This is especially true for documents that are submitted to digital libraries and university archives, which make them available for posterity.
Unfortunately, regular PDF documents are unsuitable for long-term preservation. Fonts used in the document are often linked from the operating system, and media files could be compressed using compression algorithms that are proprietary, with intellectual property constraints. If you have any colours in your document at all, they can only be displayed with a device-dependent color-profile, which may change or become unavailable decades down the line. All of these factors mean that a PDF created today is not guaranteed to look the same, or even be readable at all, in the future.
The PDF/A standard solves this issue, by requiring the PDF to include all components necessary for its display. Font files are embedded into the PDF, and only open source compression algorithms are used for media. A device-independent color profile is embedded into the document, so the PDF-viewer of the future will know how to render the content, even if we stop using RGB.
More importantly, PDF/A compliance is the first step towards creating more accessible documents. PDF/A compliant documents include rich metadata, which allows the authorship, topic, and cataloguing information of the document to be inferred automatically. Users of screen-readers and braille displays will be better accommodated by PDF/A compliant PDFs. Although this guide does not present the creation of fully-accessible (i.e. structured) PDFs, a compliant-PDF is the first step towards universal accessibility.
What are fully reproducible builds, and what benefits does it have for LaTeX documents?
A fully reproducible build, is a compilation (i.e. build) process that guarantees a specific output, given a specific input (i.e. source code). The professional discipline of software development has made significant efforts towards reproducible builds for software, due to many well-founded security benefits. However, for LaTeX we are interested in reproducible PDFs primarily for the purposes of long-term preservation and archiving.
How can you be sure that your LaTeX source code will generate the exact same PDF, both on your laptop, and on a colleague's computer? If a historian of the future were to compile your document, could she be certain that her result was the same as your PDF from the past? LaTeX documents are not bit-for-bit reproducible. If you build your document twice, the resulting PDFs will have different hashes, even if the source code remained unchanged.
There can be many reasons why a PDF will need to be re-compiled from it's original LaTeX. If we know that the build process is fully reproducible, we can be certain that we will have the same document as the original, no matter how many years have passed.
Creating PDF/A Compliant documents in LaTeX
This tutorial will take the form of a dialectic, where I walk the reader through the steps and decisions involved. A complete configuration will only be provided at the end. This way, you will understand the reasoning behind the choices made, and gain knowledge, rather than merely correct opinion.
Levels of PDF/A Compliance:
There are three different levels of PDF/A compliance:
PDF/A-3aThealevel denotes the highest level of compliance. These are structured, tagged, and fully-accessible documents capable of text-reflowing (e.g. like an ebook). LaTeX is not capable of creating these types of PDFs at this point in time.PDF/A-3bTheblevel denotes a basic level of compliance. These documents are self-contained, and archival grade.PDF/A-3uTheulevel is simplyPDF/A-3b, with the additional bonus of keeping the text of the PDF as Unicode. This is a good idea, so we will be usingpdfxwith thea-3uoption, to create this type of document.
We will be using LuaLaTeX as the underlying LaTeX engine. Here's a quick overview of the differences between LuaLaTeX and other engines (XeLaTeX, etc.) LuaLaTeX is the successor to pdfLaTeX, and offers native Unicode support, and packages like microtype offers more features for it.
We will be loading the pdfx package in order to add PDF/A support to our document.
Note on mmap, cmap, and why we do not need them.
Please note that unlike many other guides, we will not be using mmap or cmap. These packages are used to provide character map files for our documents. However, lualatex and fontspec support modern OpenType fonts in the first place, which comes with character-maps embedded within the font files themselves. mmap and cmap do not even support the modern TU encoding (TeX Unicode) which lualatex uses.
What is the mmap package, and why do some people use it? Have you ever had the experience where you tried to copy some text from a PDF, but when you pasted the selected text, the paste was incorrect? This is because documents that contain ligatures (i.e. 'th,' 'fl,' or 'ae') render them as a single glyph, or 'character.'

{kind=link}
If the PDF does not contain a character map table, than when you select the text, it will not know that the ligature represents a combination of two actual characters. Having character-map tables is especially important for screen-reader support, or automatic text-search. Once again, we will not encounter this problem, using LuaLaTeX and modern unicode OpenType fonts.
Finding the Correct Load Order for the pdfx Package
Let's begin with a regular LaTeX document, that is similar to ones that you may have right now.
\documentclass[
12pt,
a4paper
]{article}
% Packages
\usepackage{fontspec}
\usepackage{libertinus-otf}
\usepackage{geometry}
\usepackage{microtype}
\usepackage{amsmath}
\usepackage{xcolor}
% ...
\usepackage[style=mla, backend=biber]{biblatex}
% Hyperref must be loaded last!
\usepackage{hyperref}
\title{A LaTeX Document}
\author{Shen}
\date{\today}
\begin{document}
\maketitle
\tableofcontents
\section{Introduction}
The body of the document begins here.
\printbibliography
\end{document}
A generic LaTeX document
This is the kind of document that any intermediate LaTeX user will have. We use common packages like geometry, microtype, or amsmath – and we manage our citations using biblatex. We enable unicode and font support with fontspec. This is not some contrived minimal example, but rather a realistic example – one that reflects the complexity of a paper or article. We even use hyperref and xcolor, to give our citations and footnotes blue-colored hyperlinks.
How do we make this document PDF/A compliant? Do we simply load the pdfx package at the top of our load-chain?
% Packages
\usepackage[a-3u]{pdfx}
\usepackage{fontspec}
\usepackage{libertinus-otf}
\usepackage{geometry}
\usepackage{microtype}
\usepackage{amsmath}
\usepackage{xcolor}
% ...
\usepackage[style=mla, backend=biber]{biblatex}
% Hyperref must be loaded last!
\usepackage{hyperref}A naive attempt to add PDF/A compatibility to an existing document
The above attempt will not work. The document will compile, but if your paper has any footnotes, figures, or internal links at all, hyperref would experience errors in creating hyperlinks. This issue occurs because the pdfx package loads hyperref internally, and by loading pdfx at the top of our load-chain, we end up loading hyperref first.
This is a problem. The hyperref package modifies and patches many LaTeX commands (such as \section, \footnote, etc), and this is why it must be loaded last:
Make sure comes last of your loaded packages, to give it a fighting chance of not being over-written, since its job is to redefine many LATEX commands
– Section 3: Implicit Behaviour, Hyperref manual
The pdfx package also loads xcolor internally, hence we have further duplicated our efforts with loading xcolor. Let's change our code now, to account for pdfx, and move it towards the end of our load chain.
% Packages
\usepackage{fontspec}
\usepackage{libertinus-otf}
\usepackage{geometry}
\usepackage{microtype}
\usepackage{amsmath}
% ...
\usepackage[style=mla, backend=biber]{biblatex}
% pdfx loads both hyperref and xcolor internally
% \usepackage{hyperref}
% \usepackage{xcolor}
\usepackage[a-3u]{pdfx}Moving pdfx to the bottom, which loads both hyperref and xcolor implicitly.
The above attempt will solve issues with hyperref, and now footnotes, citations, and labels will be linked properly. Hence, the first complete, working configuration, would look like this:
\documentclass[
12pt,
a4paper
]{article}
% Packages
\usepackage{fontspec}
\usepackage{libertinus-otf}
\usepackage{geometry}
\usepackage{microtype}
\usepackage{amsmath}
% ...
\usepackage[style=mla, backend=biber]{biblatex}
% pdfx loads both hyperref and xcolor internally
% \usepackage{hyperref}
% \usepackage{xcolor}
\usepackage[a-3u]{pdfx}
\title{A LaTeX Document}
\author{Shen}
\date{\today}
\begin{document}
\maketitle
\tableofcontents
\section{Introduction}
The body of the document begins here.
\printbibliography
\end{document}Complete, working example for PDF/A-compliant document
Managing PDF Metadata, and hyperref Configuration
The above example will work, but our document is not complete yet. PDF/A requires us to specify certain document metadata, which will be used to help cataloguing, as well as make it easier for automated tools to injest our PDF. The pdfx documentation manual states:
Standards-compliant PDF documents require document-level metadata to be included. This, known as an ‘XMP packet,’ is like having a library catalog card included within the PDF itself.
...
[The advantages of this metadata are:]
For a librarian: cataloguing information is available within the file itself, without the need to search explicitly in the visual layout of the content or elsewhere;
All actual libraries cataloguing this PDF can have consistent information; including web-based indexing sites such as Google.
For the author(s): who can specify the kind of information most appropriate to help readers understand the nature and purpose of the document.
This metadata is also read by PDF-viwers, which allows them to display the title of the document in the window bar of the PDF viewer, for example.
So how do we include this XMP-packet of metadata? Users who are familiar with hyperref may specify their document's metadata like this, alongside other hyperref-specific configuration options:
\usepackage[
% First specify PDF metadata with hyperref
pdftitle = {A PDF-A Tutorial},
pdfauthor = {Shen},
pdfsubject = {A guide on creating PDF-A compliant documents},
pdfcreator = {LuaLaTeX},
% Now configure settings for hyperref itself
colorlinks = true,
allcolors = blue,
]{hyperref}An example of how PDF-metadata is commonly added using hyperref
You might also use hyperref's command \hypersetup to specify these options separately from the package load (which is good practice):
\usepackage{hyperref}
% ...
\hypersetup{
% First specify PDF metadata with hyperref
pdftitle = {A PDF-A Tutorial},
pdfauthor = {Shen},
pdfsubject = {A guide on creating PDF-A compliant documents},
pdfcreator = {LuaLaTeX},
% Now configure settings for hyperref itself
colorlinks = true,
allcolors = blue,
}Another example of a common way that PDF-metadata is defined, this time using \hypersetup.
Some clever people may even the pdfusetitle option in hyperref at load, which automatically defines the pdftitle and pdfauthor, attributes from the document's \title and \author declarations:
\usepackage[pdfusetitle, colorlinks=true, allcolors=blue]{hyperref}A third example of how PDF-metadata is defined with hyperref.
Unfortunately, none of the above methods will work using the pdfx package. The pdfx package requires the PDF's metadata to be specified in a separate .xmpdata file, because it needs to do transform the metadata into a specific XMP packet that is then embedded into the PDF.
This .xmpdata is given the same name and in the same location as our primary .tex file. If your document is called paper.tex, than you'll have to create a paper.xmpdata file in the same location. An example .xmpdata file will look like this:
\Author{Shen}
\Title{
Default PDF Document Title (For PDF/A Compatibility)
}
\Language{English}
\Keywords{keyword1\sep keyword2\sep keyword3}
\Publisher{Self-Published}
\Subject{
Description of the PDF's subject
}
\Date{2022-02-26}
\PublicationType{pamphlet}
\Source{https://github.com/ShenZhouHong/latex-essay}
\URLlink{https://github.com/ShenZhouHong/latex-essay}
An example of how a .xmpdata file looks like
It uses the same syntax as TeX, and we specify our metadata in this document. The pdfx documentation on CTAN.org lists other fields and options. Now, when we compile the document, the pdfx package will automatically seek out and find the .xmpdata file.
It is important to keep in mind that we cannot use the pdfusetitle option for hyperref anymore, and attempting to pass that option will result in an error.
Now, the only thing we must do is to pass the regular options we use for hyperref through \hypersetup, since we are not loading hyperref directly anymore, and cannot pass options to it from the \usepackage line.
Complete Example of PDF/A-Compliant Document
Hence, the complete example of our PDF-A compliant document will look like this:
\documentclass[
12pt,
a4paper
]{article}
% Packages
\usepackage{fontspec}
\usepackage{libertinus-otf}
\usepackage{geometry}
\usepackage{microtype}
\usepackage{amsmath}
% ...
\usepackage[style=mla, backend=biber]{biblatex}
% pdfx loads both hyperref and xcolor internally
% \usepackage{hyperref}
% \usepackage{xcolor}
\usepackage[a-3u]{pdfx}
% We use \hypersetup to pass options to hyperref
\hypersetup{
colorlinks = true,
allcolors = blue
% ...
}
\title{A LaTeX Document}
\author{Shen}
\date{\today}
\begin{document}
\maketitle
\tableofcontents
\section{Introduction}
The body of the document begins here.
\printbibliography
\end{document}The paper.tex file
And here is the corresponding paper.xmpdata file. Remember to place it in the same directory as your main .tex file (i.e. the one that you run lualatex on).
\Author{Shen}
\Title{
Default PDF Document Title (For PDF/A Compatibility)
}
\Language{English}
\Keywords{keyword1\sep keyword2\sep keyword3}
\Publisher{Self-Published}
\Subject{
Description of the PDF's subject
}
\Date{2022-02-26}
\PublicationType{pamphlet}
\Source{https://github.com/ShenZhouHong/latex-essay}
\URLlink{https://github.com/ShenZhouHong/latex-essay}
The paper.xmpdata file
Congratulations! Now you have created a fully PDF-A compliant document!
Checking for PDF-A Compliance using PDF Validation Tools
The last step that we can take is to check for our document's compliance. Adobe Acrobat Pro's Preflight tool is still the gold standard in this area, as Adobe has been instrumental in developing the PDF standard as a whole. However, there are also quality open-source validators that function nearly as well, if not identically.
We will be checking our resulting PDF document for PDF/A-compliance using the Open Preservation Foundation's VeraPDF tool. VeraPDF is an open source (GPLv3+), cross-platform PDF standard validator that's available on Windows, Mac OS, and Linux. It's a Java program, so you will have to install a Java Runtime. I recommend using the OpenJDK JRE. The latest version is available on Ubuntu simply as the default-jre apt package:
sudo apt install default-jreThe VeraPDF tool can be downloaded from the Open Preservation Foundation's website, which is linked here. It comes as a .zip file with an verapdf-install shell script and verapdf-install.bat file. For linux, you'll want to execute the verapdf-install script, by first granting it executable permissions:
chmod +x verapdf-install
./verapdf-installThis would start the GUI installer, and allow you to install the validator into a directory /verapdf at a location of your choice. We can run the GUI validator by simply executing it from the terminal like before:
chmod +x verapdf-gui
./verapdf-guiThe only slightly tricky part left is that if you are using a modern, high-resolution display, the Java program might not have a GUI that's large enough. The first time I ran the program, it looked like this, and was unusable:
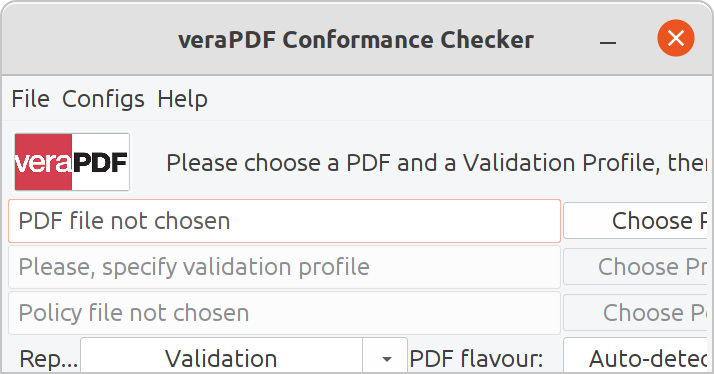
A simple fix for that is to open the ~/verapdf/verapdf-gui file. It's a simple shell script that launches the Java GUI program, and all you have to do is to change the SCALE_FACTOR=1.0 line to a larger integer, like 1.5 or 2.0.
Now the GUI is appropriately sized. All we have to do is to select our PDF, and click Execute. VeraPDF will tell us if the document is compliant with our variant of the PDF/A standard.
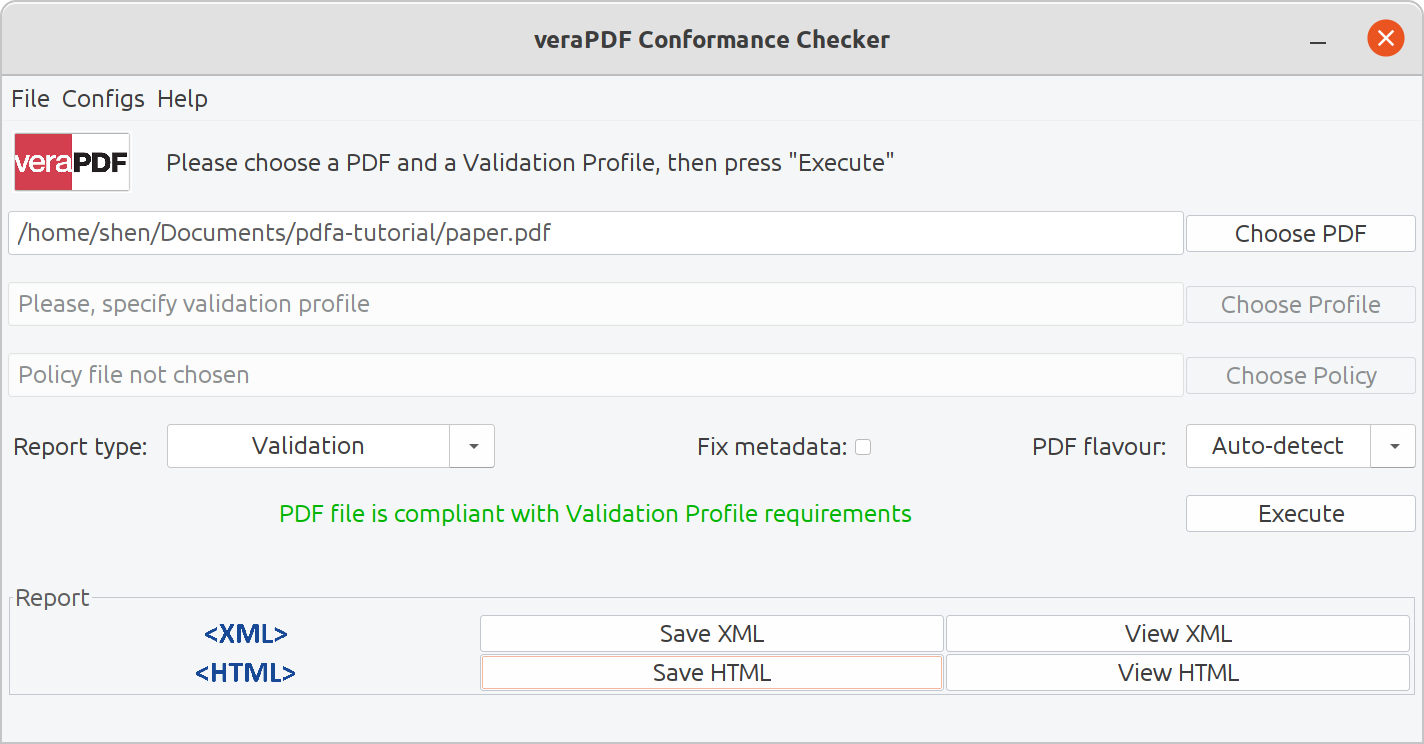
Congratulations on creating your first PDF/A-compliant LaTeX document!
Fully Reproducible LaTeX Documents using Makefile
All that remains for us to do now, is to make this document fully reproducible, so that compilations of the same source code will always result in a PDF with the same hash.
Creating fully bit-by-bit reproducible programs is quite difficult for regular software programming, but for LaTeX it is quite easy. First, we must make sure we are not using any LaTeX commands that change over time. The only common one would be the \date{\today} line. We'll remove that to specify a specific date.
Finally, the pdfx package embeds the creation date and modification date of the file into the PDF itself. As that changes every time we run lualatex, this will result in PDF files with different hashes. Thankfully, lualatex respects the SOURCE_DATE_EPOCH environment variable.
SOURCE_DATE_EPOCH is a standardised environment variable that is read by compilers and build toolchains to set the modification date of a binary (or a PDF file) to a specific date and time. It's a specification made by the Reproducible Builds project.
The variable takes an integer that represents the number of seconds elapsed since the Unix epoch, and we can get that integer for today by simply running:
date +"%s"Getting the Unix epoch time (in seconds) of the current date and time.
If you are running lualatex directly in the terminal, all you have to do to make your document reproducible, is to export this variable (for a set value, of course), and have it be available every time you run lualatex:
export SOURCE_DATE_EPOCH=1646013411
lualatex paper.texDefining the SOURCE_DATE_EPOCH on a fixed time.
This is a little burdensome, and besides, you'll have to write down whatever epoch you started with. Furthermore, it would be strange having the creation-date and modification-date of the document fixed permanently.
A much better way to use SOURCE_DATE_EPOCH to make our LaTeX documents reproducible, is to use a Makefile, and tie the SOURCE_DATE_EPOCH to the time of our latest git commit.
SOURCE_DATE_EPOCH=$(git log -1 --pretty=%ct)Defining the SOURCE_DATE_EPOCH based on the time of the latest git commit
This way, we'll always have a realistic modification date for our PDF documents, that'll remain constant for every given commit. By doing so, you'll be certain that your git repository will produce definite PDFs for every commit in it's history, that will be bit-for-bit identical. We'll create a Makefile in the directory where our paper.tex and paper.xmpdata files are located:
COMMIT_EPOCH = $(shell git log -1 --pretty=%ct)
# Makes sure latexmk always runs
.PHONY: paper.pdf all clean
all: paper.pdf
paper.pdf: paper.tex
SOURCE_DATE_EPOCH=$(COMMIT_EPOCH) latexmk -pdf -lualatex -use-make $<
clean:
latexmk -c
delete:
latexmk -CExample makefile for paper.tex that uses the date of the latest git commit
Now, every time you run make to compile your PDF, you can be certain that the resulting document is fully reproducible. And of course, if you are using this makefile in a project that does not use git, simply set COMMIT_EPOCH to a fixed value.
Conclusion
Now your document is both PDF/A compliant, as well as fully reproducible. You can be reassured that your documents will be available, even many decades into the future. Should you ever need to recompile the PDF from source, you'll get to verify that the outputs are the same by comparing the hashes of the new PDF, with the old PDF.
Creating reproducible, PDF/A compliant documents is increasingly important. As organisations and universities expand their digital archives, PDF/A compliance is increasingly becoming a requirement for many types of documents.
LaTeX Template for the Humanities
If you are interested in creating PDF/A compliant, fully-reproducible documents, make sure to also check out my LaTeX essay template! Over the course of four years, I have created and refined a simple LaTeX template for writing in the academic humanities. It implements the contents of this tutorial, and more, offering features such as:
- Custom Microtype Protrusion Settings for Hanging Punctuation.
- Typography Tweaks, Adjustments, and Custom Headers and Footers.
- BibLaTeX Integration for Citation Management
The template is available on Github, and it's open source. Feel free to check it out for inspiration!
Thank you for reading my LaTeX guide! I also write essays on Philosophy, Metaphysics, and NixOS. Let me know if you have any suggestions, comments, or advice – I always enjoy conversations with interesting strangers! If you want to be notified of future content, feel free to subscribe to my RSS feed.